この記事は?
この記事は、MLSE Advent Calendar 2019の24日目の記事です。大変遅くなったことをお詫びいたします。
この記事の内容は?
GoogleのDistinguished EngineerであるDavid Pattersonの、2019年10月にワシントン大学で行われた講演Domain Specific Architectures for Deep Neural Networks: Three Generations of Tensor Processing Units (TPU’s)のTPUに関する部分のまとめです。
TPUv3の概要が公開されたのはおそらく初めてだと思うので、機械学習システムの視点からTPU v2/v3の違いを知りたくてまとめてみました。
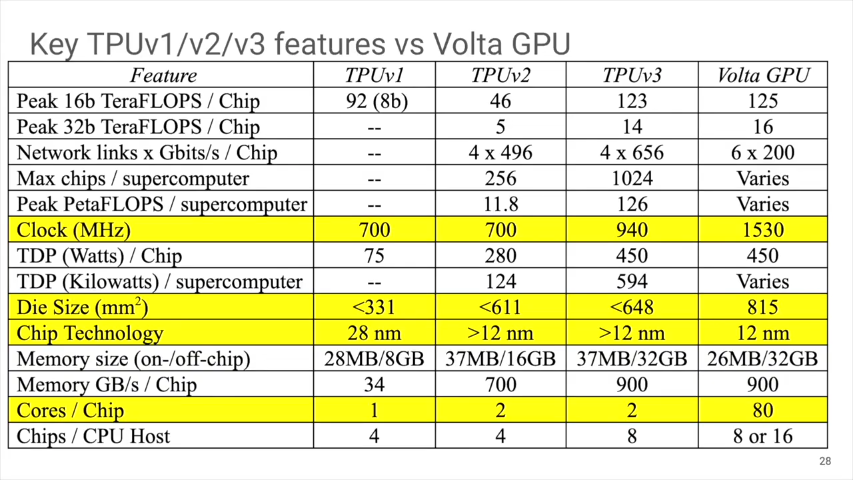
一刻も早く違いが知りたい、という人は講演中の下記のスライド に、TPU v1/v2/v3の比較がまとめられています(以下、全てのスライドはYouTubeからの引用)。
講演の内容について
(注)講演は以下の3つの話題を扱っていますが、このまとめでは最初のTPU、についてだけ触れます。
- TPU
- XLAコンパイラ
- ベンチマーク
この講演は、以下の2つのpaperが元になっています(2つ目はまだ出版されていないので、初めて聞く話もあるだろう、と話しています)。
- A Domain-Specific Architecture for Deep Neural Networks, Jouppi, Young, Patil, and Petterson, Communications of the ACM, September 2018
- A Domain-Specific Supercomputer for Training Deep Neural Networks, Jouppi, Yoon, Kurian, Li, Patil, Laudon, Young, and Patterson, Communications of the ACM, Summer 2020 (to appear)
TPUの最初のストーリー(つまりTPUv1について)
2013年にdeep neural network(DNN)の新しいアプリの需要が爆発的に増えたので、DNNの推論のTotal Cost of Ownership(TCO)を10倍減らすことを目的にして、カスタムハードウェアを作ることにしました。非常に短い期間でTPUv1は開発されました。具体的には、2014年に始めて、15ヶ月後にデータセンターで使われていました。アーキテクチャ開発、ハードウェアデザイン、コンパイラ開発、テスト、デプロイ、全てをこの間に行いました。

TPUv1のアーキテクチャ
700MHzのクロックで動作し、65536の8bit integer Multiply-acculate (MAC) unit、4MiBのon-chip accumulatorメモリ、24MiBのon-chip activationメモリ、を持ちます。
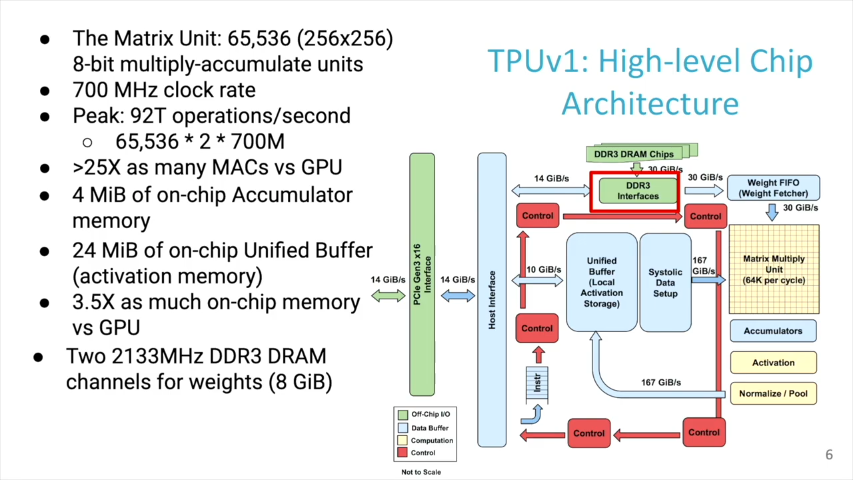
activation bufferとMACは、性能に大きく関わる部分で、チップ面積の半分を占めます。
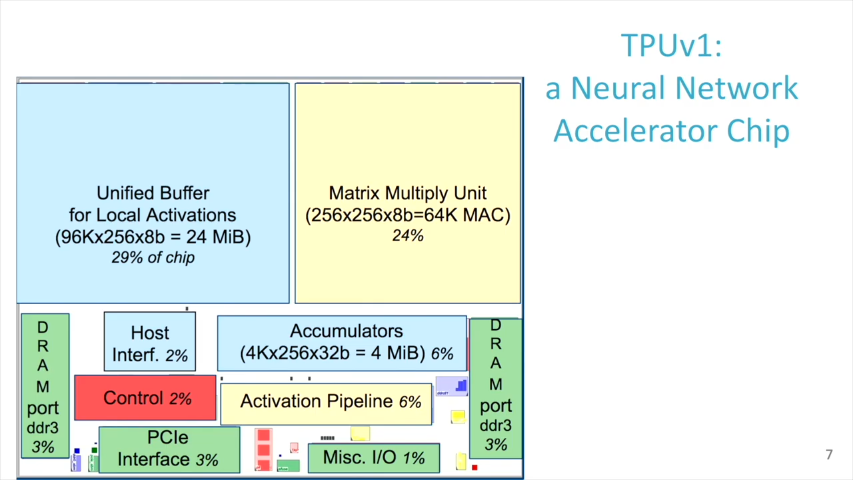
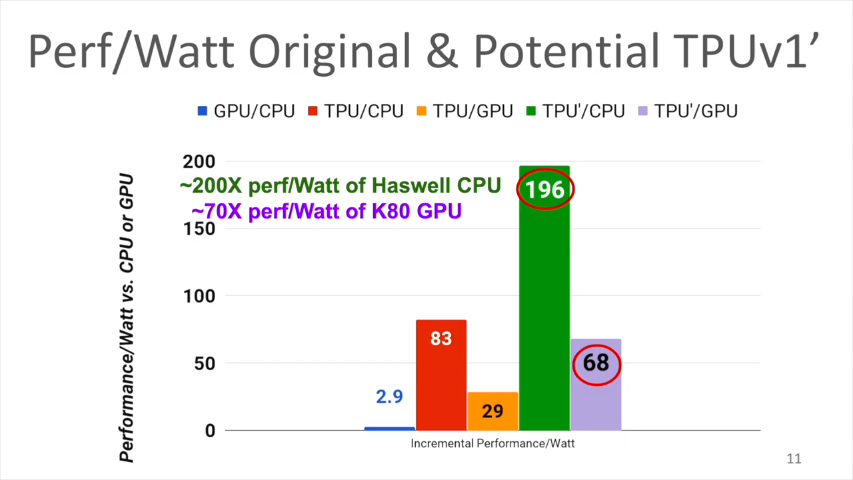
通常のプロセッサやGPUでは、MACでSRAMやレジスタにアクセスすることによって電力消費が発生します。これを減らすために、TPUではSystolic executionといわれる実行方法をとりました。性能/電力比は、対CPU(Haswell)で83倍、対GPU(K80)で29倍、改善されました。
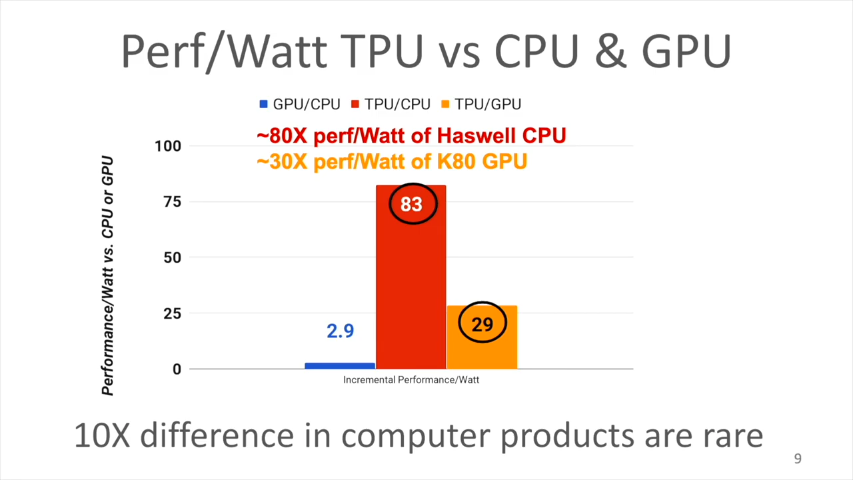
TPUv1の改善可能だった点
もしも、もっと開発時間があったとしたらどんなことをするべきだったか、というシミュレーションをしてみました。MXUを大きくする、クロックを上げる、速いメモリを使う、など。
TPUv1ではメモリは標準のものを使ったので、それほど速くないです。もしDDR3 DRAMからGDDR5に変えることができたら(TPU’)、メモリ帯域は34GB/sから180GB/sになります。すると、性能/電力比は、対CPU(Haswell)で196倍、対GPU(K80)で68倍、改善されるであろうという見込みがえられました。
TPUv1がうまくいった理由
以下の4つだと思います。
- 1次元ではなく、大きな2次元のMACユニットを用意したこと。
- 8-bit integerを採用したこと。
- Systolic arrayを採用したこと。
- キャッシュ、分岐予測といった、汎用CPU/GPUが持つ機能を採用しなかったこと。

TPUv2について
2014年に訓練(training)用として開発がはじまって、2017年にデータセンターにデプロイされました。
訓練はなぜ難しい?
以下の5つだと思います。
- より計算が必要であること。
- よりメモリが必要であること。
- よりプログラム可能であること。
- 桁数の多い数値を扱うこと。
- 並列化が易しくないこと。

訓練は計算量が多い仕事なので、machine learningにおいてブレークスルーを起こすためには、クラスタで構成される高速なSuper computerを作る必要があります。そのためには、ネットワークが重要です。 TPUv2チップは、Inter-core interconnection(ICI)を4つ内蔵しています。 - 両方向で500Gbit/sの転送速度。
- 2Dトーラスを構成します。
- TPUv2チップを、wireを介して、ラック間であっても直接接続できます。
- ICIはTPUv2ダイの13%しか使っていません。
- 一般のデータセンターに比べて、5倍のバンド幅を、1/10のコストで実現しました。

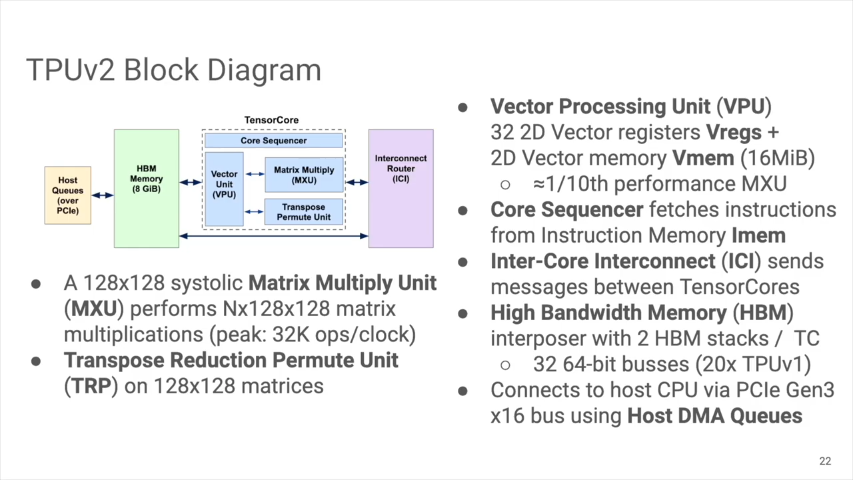
TPUv2のブロックダイヤグラム
- 128x128のMatrix Multiply Unit (MXU)
- 128x128のmatricesをTranpose, reduction, permuteするユニット(TRP)
- 32の2Dベクタレジスタと、2Dベクタメモリ(16Mib)を持つベクタユニット(VPU)。性能はMXUの1/10程度です。
- 1つのtensor coreあたり
2つのHBM stackと64-bitバスで繋ぎました2つのHBM stackを32本の64-bitバスで繋ぎました(*1)(トータルでTPUv1の20倍のバンド幅を確保しました。TPUv1でメモリバンド幅が足りなかった、という教訓を反映させました)。
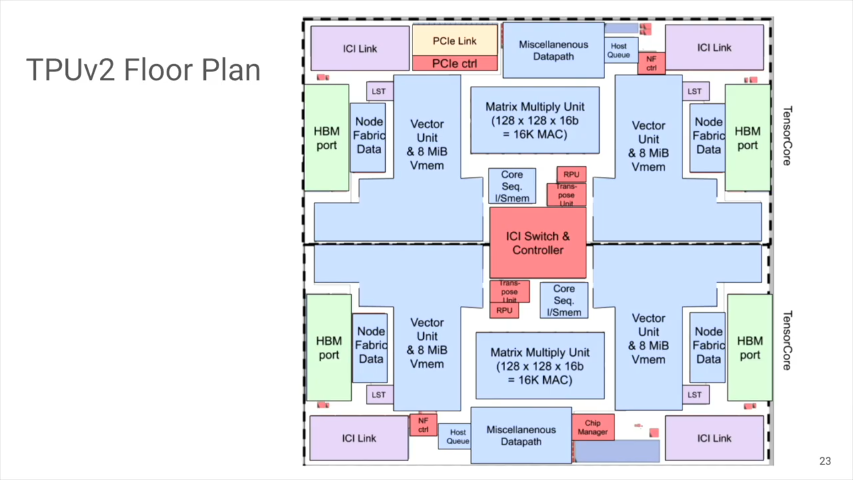
フロアプランを見ると、TPUv1と違いTPUv2ではMXUはそれほど大きな部分を占めてはいません。
TPUv2の開発中に、neural network業界に何が起きたか?
2015年にBatch normalization、が登場! Batch normalizationがneural networkの精度を改善して、訓練時間を1/14まで短縮しました。
TPUv2では、ソフトとハードで対応しました。
- ソフトウェア: Batch normalizationを、バッチに対する足し算と掛け算に分解して、inverse square-rootを行います。
- ハードウェア: ベクタユニットのスループットを、最初のデザインより8倍にしました。inverse square root用のハードを追加しました。

TPU2のInstruction set architecture(ISA)
8演算まで同時実行可能な、322-bitのVLIW命令からなります。
- 2つのスカラarithmetic演算
- 2つのベクタarithmetic演算
- 1つのベクタロード
- 1つのベクタストア
- 2つのMXUとTRPユニットとのやり取りのためのキュー
メモリ・レジスタは以下のようなものがあります。 64K 命令メモリ 32 32-bit スカラレジスタ 4K 32-bit スカラメモリ 32 128x8 32-bit ベクタレジスタ 32K 128 32-bit ベクタメモリ

TPUv3について
TPUv3は、TPUv2と同じテクノロジを使っています。違いは、
- クロックレート、ICIバンド幅、 HBMバンド幅、1.35倍に増加
- 1チップで、コアあたりのMXUを1から2に増加
- ダイの大きさは6%しか増えていない
- 結果、消費電力1.6倍になったので、液冷を使用
- HBMのメモリ容量を2倍にして、コアあたり16GiBに
- システム全体では、256から1024チップに増加


TPUv1/v2/v3の比較表は、この記事の最初にあります。
(*1)Twitterで@Vengineerさんからご指摘を頂き修正しました。